
Module providing Consciousness Exploration Tools for PyTorch.
Note
Click here to download the full example code
Spatiotemporal Trajectories in Resting-state FMRI¶
Credit: A Grigis
In this example we illustrate how we can extract meaningful spatiotemporal information from a Variational Auto-Encoder (VAE) using rfMRI data.
The test variable must be set to False to run a full training.
import os
import sys
import time
import copy
from pprint import pprint
import numpy as np
import matplotlib.pyplot as plt
import torch
from dataify import SinOscillatorDataset
from brainite.models import VAE
from brainite.losses import BetaHLoss
from brainite.utils import traversals
from consciousnet.plotting import plot_reconstruction_error
from consciousnet.plotting import plot_spatiotemporal_patterns
test = True
n_samples = 20
adam_lr = 0.01
batch_size = 10
n_epochs = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Sinus oscillator dataset¶
Fetch/load the SinOscillator dataset.
dataset = SinOscillatorDataset(
n_samples=n_samples, duration=4, fs=10, freq=(0.6, 0.7),
amp=1, phase=np.pi, target_snr=20, seed=42)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, num_workers=1)
item = next(iter(dataloader))
print(item.shape)
Out:
torch.Size([10, 40, 1])
Training¶
Train a VAE with 1-D temporal convolutions.
def train_model(dataloader, model, device, criterion, optimizer,
scheduler=None, n_epochs=100, checkpointdir=None,
save_after_epochs=1, board=None, board_updates=None,
load_best=False):
""" General function to train a model and display training metrics.
Parameters
----------
dataloader: torch.utils.data.DataLoader
the data loader.
model: nn.Module
the model to be trained.
device: torch.device
the device to work on.
criterion: torch.nn._Loss
the criterion to be optimized.
optimizer: torch.optim.Optimizer
the optimizer.
scheduler: torch.optim.lr_scheduler, default None
the scheduler.
n_epochs: int, default 100
the number of epochs.
checkpointdir: str, default None
a destination folder where intermediate models/histories will be
saved.
save_after_epochs: int, default 1
determines when the model is saved and represents the number of
epochs before saving.
board: brainboard.Board, default None
a board to display live results.
board_updates: list of callable, default None
update displayed item on the board.
load_best: bool, default False
optionally load the best model regarding the loss.
"""
since = time.time()
if board_updates is not None:
board_updates = listify(board_updates)
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = sys.float_info.max
dataset_size = len(dataloader)
model = model.to(device)
for epoch in range(n_epochs):
print("Epoch {0}/{1}".format(epoch, n_epochs - 1))
print("-" * 10)
model.train()
running_loss = 0.0
for batch_data in dataloader:
batch_data = torch.transpose(batch_data, 1, 2)
batch_data = batch_data.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward:
# track history if only in train
with torch.set_grad_enabled(True):
outputs, layer_outputs = model(batch_data)
criterion.layer_outputs = layer_outputs
loss, extra_loss = criterion(outputs, batch_data)
# Backward + optimize only if in training phase
loss.backward()
optimizer.step()
# Statistics
running_loss += loss.item() * batch_data[0].size(0)
if scheduler is not None:
scheduler.step()
epoch_loss = running_loss / dataset_size
print("Loss: {:.4f}".format(epoch_loss))
if board is not None:
board.update_plot("loss", epoch, epoch_loss)
# Display validation classification results
if board_updates is not None:
for update in board_updates:
update(model, board, outputs, layer_outputs)
# Deep copy the best model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
# Save intermediate results
if checkpointdir is not None and epoch % save_after_epochs == 0:
outfile = os.path.join(
checkpointdir, "model_{0}.pth".format(epoch))
checkpoint(
model=model, outfile=outfile, optimizer=optimizer,
scheduler=scheduler, epoch=epoch, epoch_loss=epoch_loss)
print()
time_elapsed = time.time() - since
print("Training complete in {:.0f}m {:.0f}s".format(
time_elapsed // 60, time_elapsed % 60))
print("Best val loss: {:4f}".format(best_loss))
# Load best model weights
if load_best:
model.load_state_dict(best_model_wts)
def listify(data):
""" Ensure that the input is a list or tuple.
Parameters
----------
arr: list or array
the input data.
Returns
-------
out: list
the liftify input data.
"""
if isinstance(data, list) or isinstance(data, tuple):
return data
else:
return [data]
def checkpoint(model, outfile, optimizer=None, scheduler=None,
**kwargs):
""" Save the weights of a given model.
Parameters
----------
model: nn.Module
the model to be saved.
outfile: str
the destination file name.
optimizer: torch.optim.Optimizer
the optimizer.
scheduler: torch.optim.lr_scheduler, default None
the scheduler.
kwargs: dict
others parameters to be saved.
"""
kwargs.update(model=model.state_dict())
if optimizer is not None:
kwargs.update(optimizer=optimizer.state_dict())
if scheduler is not None:
kwargs.update(scheduler=scheduler.state_dict())
torch.save(kwargs, outfile)
model = VAE(
input_channels=1, input_dim=40, conv_flts=[16], dense_hidden_dims=None,
latent_dim=8, noise_fixed=True, act_func=None, dropout=0, sparse=False)
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=adam_lr)
criterion = BetaHLoss(beta=1, use_mse=True)
train_model(dataloader, model, device, criterion, optimizer,
n_epochs=n_epochs)
Out:
VAE(
(encode): Encoder(
(w_conv): Sequential(
(0): Conv1d(1, 16, kernel_size=(3,), stride=(2,), padding=(2,))
(1): ReLU()
)
(w_mu): Linear(in_features=336, out_features=8, bias=True)
(w_logvar): Linear(in_features=336, out_features=8, bias=True)
)
(decode): Decoder(
(w_dense): Sequential(
(0): Linear(in_features=8, out_features=336, bias=True)
(1): ReLU()
)
(w_conv): Sequential(
(0): ConvTranspose1d(16, 1, kernel_size=(3,), stride=(2,), padding=(2,))
)
)
)
Epoch 0/9
----------
Loss: 70.7578
Epoch 1/9
----------
Loss: 57.1459
Epoch 2/9
----------
Loss: 50.0528
Epoch 3/9
----------
Loss: 45.2372
Epoch 4/9
----------
Loss: 40.2789
Epoch 5/9
----------
Loss: 36.3599
Epoch 6/9
----------
Loss: 31.5541
Epoch 7/9
----------
Loss: 26.9338
Epoch 8/9
----------
Loss: 24.4136
Epoch 9/9
----------
Loss: 21.1657
Training complete in 0m 0s
Best val loss: 21.165733
Exporing VAE¶
Train a VAE with 1-D temporal convolutions.
def test_model(dataloader, model, device):
""" General function to test a model.
Parameters
----------
dataloaders: dict of torch.utils.data.DataLoader
the train & validation data loaders.
model: nn.Module
the trained model.
device: torch.device
the device to work on.
"""
was_training = model.training
model.eval()
data, rec_data = [], []
with torch.no_grad():
for idx, batch_data, in enumerate(dataloader):
batch_data = torch.transpose(batch_data, 1, 2)
data.append(batch_data.numpy())
batch_data = batch_data.to(device)
outputs, layer_outputs = model(batch_data)
rec_data.append(VAE.p_to_prediction(outputs))
model.train(mode=was_training)
data = np.concatenate(data, axis=0).squeeze()
rec_data = np.concatenate(rec_data, axis=0).squeeze()
return data, rec_data
n_samples = 30
sigma = 3
st_patterns = traversals(
model, device, n_per_latent=n_samples, max_traversal=sigma)
plot_spatiotemporal_patterns(st_patterns, sigma, channel_id=0)
data, rec_data = test_model(dataloader, model, device)
similarity = plot_reconstruction_error(data, rec_data)
pprint(similarity)
plt.show()
![Temporal patterns using [$-3\sigma$, $+3\sigma$] traversal](../_images/sphx_glr_plot_rfmri_spatiotemporal_trajectories_via_stvae_001.png)
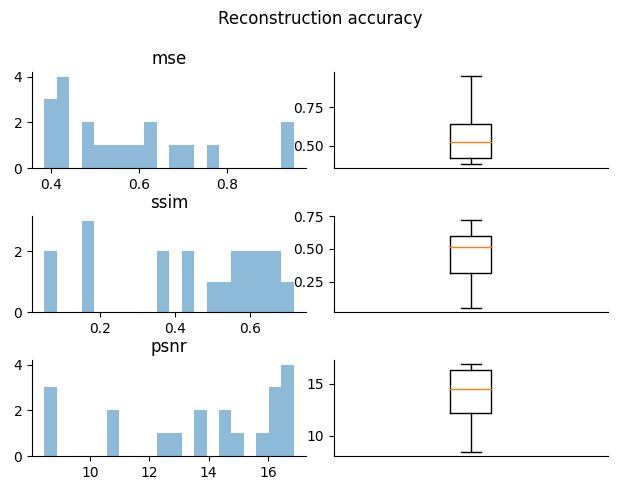
Out:
{'mse': [0.9502125656649533,
0.48259322248709074,
0.4225788807653426,
0.6151278959766967,
0.41156692369676595,
0.5930411676593978,
0.4165519378044954,
0.7029929614671026,
0.3955209637070065,
0.4246777617686241,
0.4780044589711214,
0.533278849227867,
0.5191246086429293,
0.38555824473047073,
0.9472820009450422,
0.4194173940471206,
0.5594418570766992,
0.690453309367109,
0.7720104628937136,
0.6275081129374874],
'psnr': [8.460946494002119,
16.330380378451366,
16.1657131334532,
12.600437820070018,
15.92681640790337,
13.605788486267551,
16.583172984349616,
10.969146720241268,
16.675783526944908,
16.354647910963468,
15.165761896858836,
14.482101126869741,
13.914333531153005,
16.87661705155452,
8.851072221437715,
16.541187368648945,
14.440230381438736,
8.857194244754501,
10.726193057689436,
12.77489608125925],
'ssim': [0.05277294706355001,
0.5873707330785849,
0.666674135800318,
0.3609625391679268,
0.6667564565440832,
0.4451002825282266,
0.5804811310714247,
0.17626907710112558,
0.588758499687514,
0.7168040653141602,
0.5776706901437951,
0.5103136252939117,
0.5202006427848191,
0.6412705170300343,
0.07539837167737792,
0.6211473588174551,
0.448288902418531,
0.18457154540151244,
0.16377338358826443,
0.378989674087098]}
Total running time of the script: ( 0 minutes 1.884 seconds)
Follow us